
[논문 리뷰] Wide & Deep Learning for Recommender Systems
Updated:
Recommender System
wide and deep은 2016년에 구글이 발표한 추천랭킹 알고리즘이다. 이는 구글 플레이의 앱 추천에 사용되며, 구체적으로 user의 검색 query를 바탕으로 생성된 candidate 앱을 정렬하는데 적용된다. 본 논문은 비교적 쉽게 읽을 수 있으며, 딥러닝 기반 추천시스템의 입문용 논문으로 제격이라 생각한다.
Abstract
흔히 regression이나 classification 문제를 풀때, linear 모델을 사용한다. 이때 feature간의 cross-product는 데이터의 특징을 기억하는데 효과적이다. 하지만 일반화를 위해서는 공수가 많이드는 엔지니어링 과정을 거쳐야한다. 반면 임베딩을 활용한 neural net 모델은 엔지니어링 노력이 덜 들고, feature간의 combination을 학습하기에도 탁월하다. 하지만 지나친 일반화로 인해 데이터의 특징을 자세히 기억하지 못하는 문제가 있다.
이런 문제에 주목해 본 논문은 memorization에 특화된 linear wide 모델과, generalization에 특화된 non-linear deep모델을 결합한 wide and deep 모델을 제안한다.
1. Introduction
먼저 wide모델과 deep모델의 특징을 간단하게 살펴보겠다. 여기서는 두 모델의 input이 어떤 차이가 있는지 볼 것이다. user가 설치한 앱 feature와, 열람한 앱 feature간의 interaction을 input으로 사용한다고 가정해보자. 이때 앱은 A, B, C 총 3개만 존재하며, user가 설치한 앱과 클릭한 앱은 아래와 같다고 하자.
\[\begin{align*} \\ &\bullet \ \ \text{user_install_app} =[A,B] \\ &\bullet \ \ \text{user_impression_app} =[A,C] \\ \\ \end{align*}\]wide모델에서는 아래 표와 같이 설치한 앱과, 열람한 앱 간의 cross-product를 통해 interaction을 표현하게 된다. 예를 들어 user가 A앱을 설치했고 동시에 C앱을 봤다면 \((A,C)=(1,1)\)로 표현가능하고, 두 값을 곱하면 1이 된다. 이런 식으로 모든 앱의 combination을 표현하면 총 9가지가 존재하고, 이때 1이 되는 경우는 단 4가지 뿐이다. 해당 방식은 1이되는 모든 경우를 학습하기 때문에 memorization에 강하고, user의 특이 취향이 반영된 niche combination을 학습하기에 탁월한 반면, 0이 되는 pair는 학습이 불가능하다는 단점이있다.

반면 deep모델은 A, B, C 앱을 동일한 임베딩 공간(여기서는 2차원 가정)에 표현한다. 따라서 \((C,B)\)처럼 pair가 없는 관계도 결국 같은 임베딩 공간 내에서 표현이 되기 때문에 학습이 가능하다. 하지만 niche combination의 경우 다른 user들에게서는 거의 등장하지 않기 때문에, 앱을 표현할 충분한 정보가 부족하다. 따라서 이런 앱들은 다른 앱과의 관계를 제대로 표현하지 못한 임베딩 벡터를 가질 가능성이 크다. deep모델에서 두 feature간interaction은 아래 오른쪽 그림처럼 multi-layer가 만든 non-linear 공간에서 표현된다. 따라서 generalization에 강한 반면, 희소한 앱들은 학습이 잘 안되기 때문에 전혀 관계없는 아이템들이 추천이 될 수도 있다.

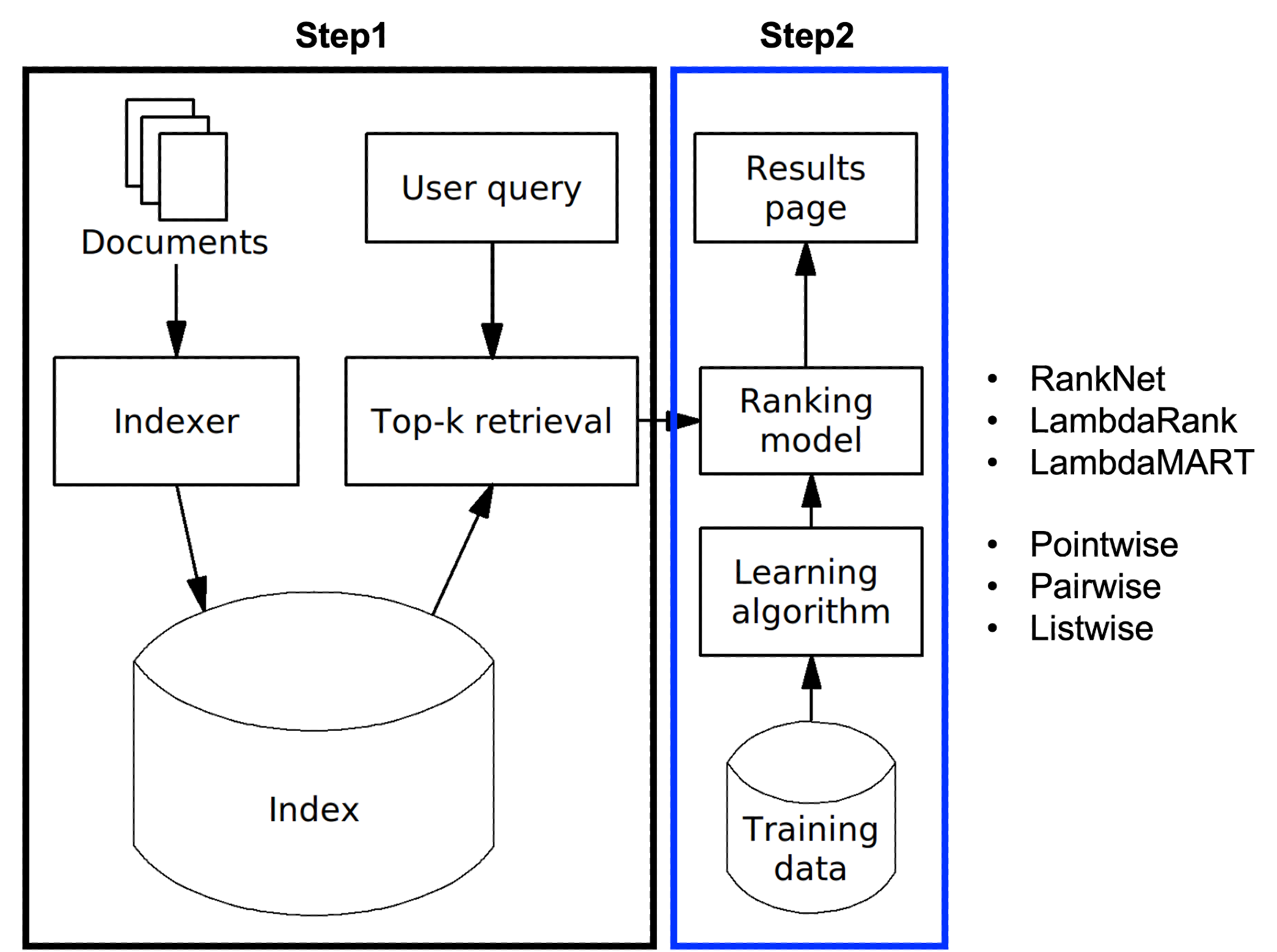
2. Recommender system overview

위 그림은 앱 추천시스템의 오버뷰다. 먼저 user의 검색 query가 들어오면, database로부터 해당 query에 적합한 후보 앱들을 retrieval한다. 이어 ranking 알고리즘을 통해 후보 앱들의 점수를 메겨 정렬한다. 여기서 점수란 구체적으로 user 정보 x가 주어졌을때, user가 y앱에 action할 확률인 \(p(y \mid x)\)를 구하는 것이 된다. wide and deep은 ranking 알고리즘으로, 여기서는 이런 후보 앱들의 점수를 메기는데 사용된다.
3. Wide & Deep learning
이제 wide모델과 deep모델을 구체적으로 살펴보자.
The wide component

wide모델은 user_installed_app, impression_app 두 feature를 cross-product한 결과 $\mathbf {x}$를 input으로 사용한다. 여기서 $\mathbf{x}$는 앞서 Introduction에서 설명한 wide모델 표의 가장 오른쪽 열에 해당한다고 보면 된다. wide모델은 아래와 같이 표현된다.
\[\\ \begin{align*} y &= \mathbf{w}^{T}\mathbf{x}+b \\ \\ where, \ \ \mathbf{x}&=[x_{1},x_{2}, ... , x_{d}] \\ \mathbf{w}&= [w_{1},w_{2}, ... , w_{d}] \\ b &= \text{bias} \end{align*}\]논문에서 설명한 cross-product transformation $\phi_{k}(\mathbf{x})$는 선형대수의 cross-product와는 다른 개념이다. $\phi_{k}(\mathbf{x})$에 대한 자세한 설명은 아래 supplement란에서 설명하겠다.
The deep component

deep모델은 continuous feature와 임베딩 된 categorical feature를 concat한 결과 $\mathbf{a}$를 input으로 사용한다. 이때 $l$번째 layer는 다음과 같은 계산을 수행한다.
\[\begin{align*} \\ \mathbf{a}^{(l)} = f(W^{(l-1)}\mathbf{a}^{(l-1)}+\mathbf{b}^{(l-1)}) \\ \\ \end{align*}\]여기서 $f$는 activation function, $W$는 weight matrix, $\mathbf{b}$는 bias를 의미한다. 위 그림에 따르면 총 3개의 layer를 쌓았으며, $f$로 ReLU를 사용했다.
Joint training of wide & deep model

이제 wide모델과 deep 모델을 joint training하는 방법을 살펴보겠다. 여기서 joint training은 여러개의 모델을 결합하는 앙상블과 달리, ouput의 gradient를 wide와 deep모델에 동시에 backpropagation하여 학습한다. 논문에 따르면, wide 모델에서는, optimizer로 online learing 방식인 Follow-the-regularized-leader(FTRL) 알고리즘을, deep 모델에서는 Adagrad를 사용했다고 한다. FTRL에 대한 자세한 설명은 다음 포스팅을 참고 바란다.
아래는 wide and deep 모델의 prediction이다. 여기서 $p(Y=1)$은 특정 앱을 acquisition할 확률로 이해하면 되겠다. 각 모델에서 나온 결과를 더해 sigmoid 함수 $\sigma(.)$를 통과 시킨 결과가 최종 output이 된다.
\[\begin{align*} \\ p(Y=1|\mathbf{x}) = \sigma(\mathbf{w}^{T}_{wide}[\mathbf{x}]+\mathbf{w}^{T}_{deep}a^{(l_{f})}+b) \end{align*} \\\]5. Conclusion
wide and deep 모델은 memorization에 특화된 wide모델과, generalization에 특화된 deep모델을 결합한 것이다. 논문에 따르면, 이는 factorization machine(fm)의 아이디어로부터 시작됐다고 한다. fm은 linear모델로, generalization을 위해서는 공수가 많이 드는 엔지니어링이 필요하다. wide and deep은 wide파트에서 linear모델을 사용하면서, deep파트에서는 복잡한 엔지니어링이 가능하도록 한 알고리즘으로, fm이 가진 이점과 한계를 모두 구현했다고 이해하면 된다. 이는 범용적인 알고리즘으로 추천 외에 여러 분야에서 사용되고 있으며, tensorflow에서 API를 제공하고 있으니 쉽게 구현해볼 수 있을 것이다.
*fm에 대한 아이디어는 deepfm 포스팅을 참고 바란다.
Supplement
cross product transformation example
예를 들어 gender, education level, language 3개의 feature가 있다고 가정해보자. 모두 binary로 가정하며, 다음과 같은 값을 갖는다고 하자.
\[\begin{align*} &\bullet \ \text{gender} = [\text{male},\text{female}] = [1,0] \\ &\bullet \ \text{education} = [\text{high},\text{low}] = [1,0] \\ &\bullet \ \text{language} = [\text{eng},\text{kor}] = [1,0] \end{align*} \\\]이제 user A가 male이면서 education level은 low에 해당하고 언어는 kor를 사용한다고 한다면, user A 벡터 $\mathbf{x}$는 다음과 같이 표현 가능하다.
\[\\ \begin{align*} \mathbf{x} = [\text{gender},\text{education},\text{language}] = [\text{male},\text{low},\text{kor}] = [1,0,0] \end{align*} \\\]만약 2가지 경우의 feature transformation $\phi_{k}(\mathbf{x})(k=1,2)$ 방법이 있다고 하자. 예를 들어 $\phi_{2}(\mathbf{x})$가 gender와 language의 조합을 나타내는 transformation이라고 한다면, $\phi_{2}(\mathbf{x})$는 다음과 같이 formulation 가능하다.
\[\\ \begin{align*} \phi_{2}(\mathbf{x}) = x_{1}^{c_{21}} x_{2}^{c_{22}} x_{3}^{c_{23}} = 1^{1}0^{0}0^{1} =0, \ \ \ 0^{0} \equiv 1 \end{align*} \\\]이때, $c_{2i}$는 $i(i=1,2,3)$번째 feature를 $\phi_{2}$ transformation에 사용하는지 여부를 나타낸다. 예를 들어 $\phi_{2}$는 gender와 language를 사용하는 변환이므로, $c_{2} = [c_{21}, c_{22}, c_{23}] = [1,0,1]$가 된다. user A의 경우 male이면서, eng를 사용하지 않으므로 transformation 값은 0이 된다.
Code
Wide and Deep 구현 코드
Leave a comment