
[논문 리뷰] Graph Convolutional Matrix Completion
Updated:
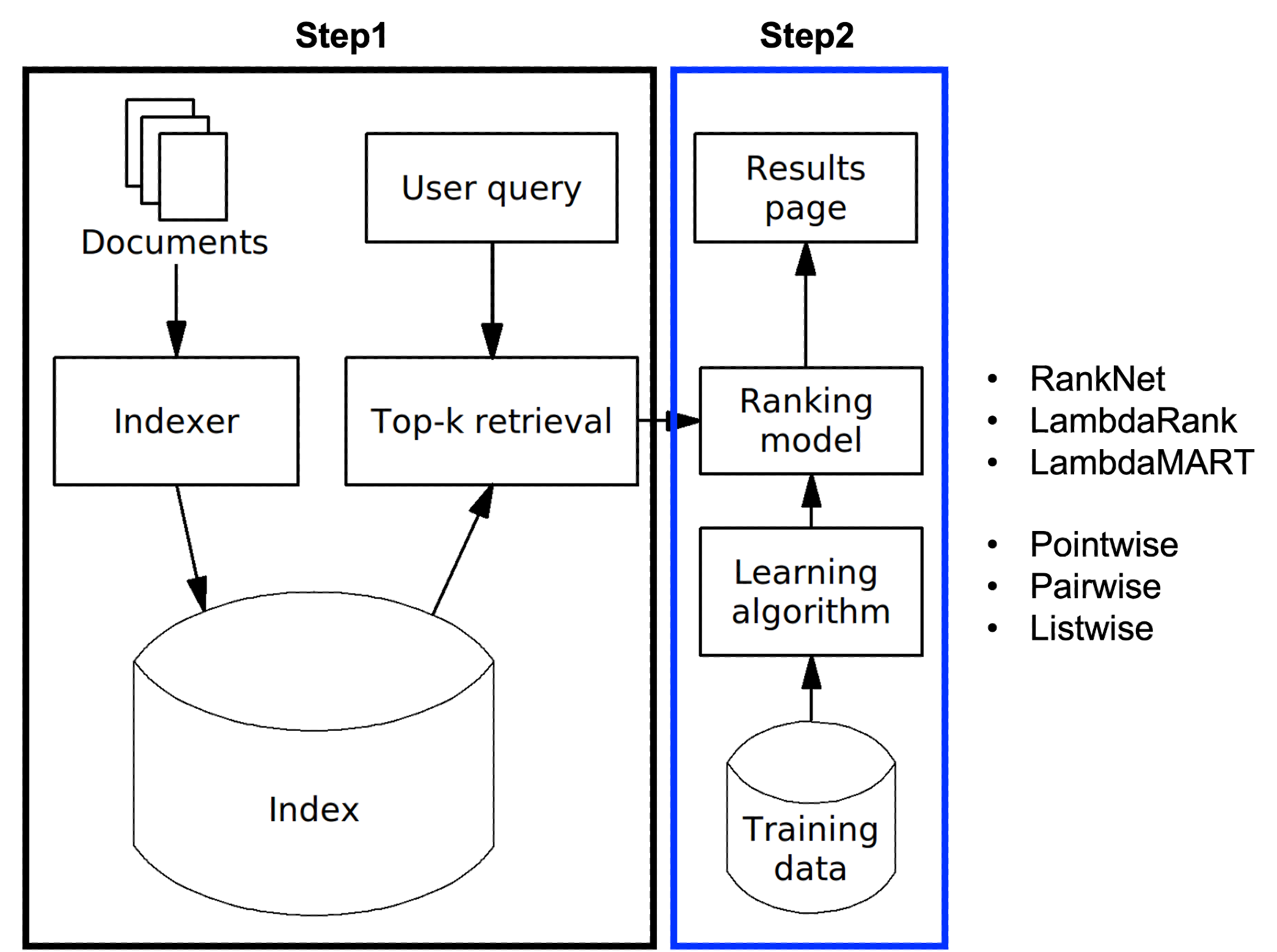
Recommender System
이번 논문은 graph based recommendation system에 대한 내용이다. 최근 추천시스템 리서치 동향을 보면 graph network 관련 논문이 상당히 많다. 해당 논문은 2017년에 발표된 것으로, 보통 social network를 graph로 표현하는 것과 달리, 우리에게 익숙한 user-item rating matrix를 graph 구조로 표현한 것이 특징이다. 데이터를 matrix가 아닌 grpah로 표현한 것만 제외하면, 풀고자 하는 문제는 matrix factorization과 본질적으로 동일하다.
Abstract
흔히 추천시스템은 matrix completion 문제를 풀게 된다. 논문은 이를 위한 방법으로 graph auto-encoder framework를 제안하는데, 이는 user-item rating matrix를 graph로 표현하여 결과적으로 rating(edge, link)을 예측하는 시스템이다. 보통의 추천 알고리즘처럼, 해당 방법도 matrix값(rating)을 예측한다는 측면에서 matrix completion 문제로 귀결된다. 논문에 따르면 이는 기존의 collaborative filtering 기법보다 우수한 성능을 보인다고 한다.
1. Introduction
본격적인 문제 정의에 앞서 graph auto-encoder framework 구조를 살펴보겠다. 이는 크게 encoder와 decoder로 이뤄져있다.

먼저 encoder 모델에서는 user, item 각각에 대한 latent vector를 구한다. 이는 마치 matrix factorization에서 svd나 다양한 추천 알고리즘을 통해 latent vector를 구하는 것과 동일하다. 이어 decoder 모델에서는 이렇게 구한 latent vector를 가지고 원래의 rating을 예측한다. 일반적으로 $u $와 $v $의 내적을 많이 사용하나, 여기에서는 decoder 모델을 별도로 정의하여 사용한다.
해당 논문에서는 encoder모델로 graph convolutional network(gcn)를 사용한다. 논문의 제목에서도 드러나듯, 여기서는 encoder 모델이 핵심이다. 사실 대부분의 추천 논문들(특히 matrix factorization 기반의 것들)은 latent vector를 ‘잘’ 추정하는 방법에 대해 고민하며, 이 논문은 그 방법으로 graph를 차용한 것이라 할 수 있다.
논문에 따르면 gcn의 또 다른 장점은 user, item에 대한 side information를 표현하기 용이하다는 것인데 이 부분은 아래에서 더 자세히 살펴보도록 하겠다.
2. Matrix completion as link prediction in bipartite graphs
본격적으로 encoder와 decoder 모델을 살펴보기 전에, 논문이 제시하는 추천시스템의 큰 그림을 살펴보겠다. 이를 위해 먼저 user-item rating matrix를 정의해야 한다. user, item 수를 각각 $N_{u}, N_{v}$라 하고, user $i$가 item $j$에 메긴 rating을 $r$이라 할 때, rating matrix $M$은 다음과 같이 표현된다.
\[\begin{align*} \\ M_{N_{u} \times N_{v}}=\begin{bmatrix} & & \\ & M_{ij} & \\ & & \end{bmatrix}, \ \ M_{ij} = \begin{cases} r & \text{observed}, \\ 0 & \text{unobserved} \end{cases} \\ \\ \end{align*}\]여기서 unobserved item은 0으로 채우는 것에 주목하자. 이 ‘unobserved’에는 user가 해당 item을 모르거나, 실제로 0점을 메긴 경우가 모두 포함된다. 사실 엄밀히 두 경우를 구분해야 되지만 여기서는 딱히 구분하지 않는다. 이제 rating matrix를 graph로 맵핑하는 방법에 대해 알아보겠다.

위 그림은 rating matrix를 graph로 표현한 것이다. 여기서 user와 item 각각은 node로, rating은 edge로 표현된다. 예를 들어 user1이 item1에 5점을 메긴 경우($M_{11}=5$)를 살펴보자. 이를 그래프로 나타내면 user1, item1의 node를 연결하고, edge에 5점을 부여하면 된다. 아래는 Introduction에서 살펴본 framework를 graph 구조와 함께 그려본 것이다.

즉 graph로 표현한 데이터로 encoder 모델을 만들고, 이로부터 user, item 각각에 대한 latent vector를 구한다. 이어 decoder 모델을 통과시켜 결과적으로 rating(edge, link)를 예측하는 시스템이되겠다. 이때 예측은 matrix의 0점 부분을 예측한다는(채운다는) 의미에서 matrix completion이라고 할 수 있다.
2.1 Graph auto-encoders
이제 encoder와 decoder의 개념을 엄밀하게 정의해보자.
Encoder
encoder 모델 $f(.)$는 다음과 같이 정의된다. 이는 앞서 user, item각각에 대한 latent vector를 구하는 것이라 하였다.
\[\begin{align*} Z_{N \times E} = \begin{bmatrix} U_{N_{u} \times E} \\ V_{N_{v} \times E} \\ \end{bmatrix} = f(X_{N \times D}, \ A_{N_{u} \times N_{v}}) = f(X, M_{1}, M_{2}, ...,M_{R}) , \ \ N=N_{u}+N_{v} \\ \end{align*}\]여기서 $U$와 $V$는 각각 user latent vector, item latent vector로 이뤄진 matrix다. 이를 각각 $u, v$로 표현하면 다음과 같다. 이때 $E$는 latent vector의 차원이다.
\[\begin{align*} u_{i(1 \times E)}\in U, \ \ \ \ &i \in \{ 1,2,...,N_{u} \} \\ v_{j(1 \times E)} \in V, \ \ \ \ &j \in \{ 1,2,...,N_{v} \} \\ \end{align*}\]이어 $X_{N \times D}$는 featrue matrix로 user, item 각각에 대한 dense vector로 이뤄진다. 예를 들어 아래처럼 각 node는 $D$차원의 featature vector를 갖는다.

마지막으로 $A_{N_{u} \times N_{v}}$는 graph adjacency matrix다. 즉 위 그래프를 바탕으로 $A$를 표현하면 다음과 같다. 즉 edge가 있는 부분은 1 없는 부분은 0이 된다.
\[\begin{align*} A =\begin{bmatrix} 1 \ \ 1 \ \ 0 \ \ 0 \\ 0 \ \ 1 \ \ 0 \ \ 0 \\ 0 \ \ 0 \ \ 1 \ \ 0 \\ 0 \ \ 0 \ \ 0 \ \ 1 \\ 0 \ \ 0 \ \ 1 \ \ 0 \\ \end{bmatrix} \\ \end{align*}\]이를 각 rating에 대해 표현할 수도 있는데, $r$점에 대한 adjacency matrix $M_{r}$은 $M_{r} \in { 0,1}^{N_{u} \times N_{v}}$로 정의된다. 예를 들어 $r=5$에 대해 adjacency matrix를 구하면 다음과 같다.
\[\begin{align*} M_{5} =\begin{bmatrix} 1 \ \ 0 \ \ 0 \ \ 0 \\ 0 \ \ 0 \ \ 0 \ \ 0 \\ 0 \ \ 0 \ \ 1 \ \ 0 \\ 0 \ \ 0 \ \ 0 \ \ 0 \\ 0 \ \ 0 \ \ 0 \ \ 0 \\ \end{bmatrix} \\ \end{align*}\]정리하자면, encoder 모델은 feature matrix $X$와, adjacency matrix $A(or M_{r})$를 갖고 latent vector를 구하는 것이라 할 수 있다.
Decoder
decoder 모델 $g(.)$는 다음과 같이 정의된다. 이는 앞서 latent vector를 갖고 rating을 예측하는 것이라 하였다.
\[\begin{align*} \hat{M}_{N_{u} \times N_{v}} = g(Z) =g(U,V) \end{align*}\]2.2 Graph convolutional encoder
이제 본 논문이 제시한 encoder 모델인 graph convolutional network(gcn)를 살펴볼 차례다. (혹시 gcn을 처음 들어보신 분은 여기를 참고바란다)
2.2.1 Convolution
gcn을 이해하기 위해서는 convolutional neural network에서 convolution이 하는 역할을 이해할 필요가 있다. gcn도 동일한 아이디어를 갖기 때문이다. 필자가 생각할 때 convolution의 핵심은 2가지다. 먼저 filter map(weight matrix)이란 것을 사용해서 추상적인(abstract) 정보를 뽑는 것과, 각 정보가 동일한 filter map을 공유(weight sharing)한다는 것이다. 아래의 예시를 보자.

Abstract feature
예를들어 숫자 9가 그려진 이미지가 있다고 치자. convolution은 이미지의 각 영역마다 이 filter를 곱해 정보를 뽑아낸다. 즉 먼저 초록색 영역에 대한 정보를 뽑고, 한칸 이동시켜 빨간색 영역에 대한 정보를 뽑는 식이다. 이런식으로 주변 영역들을 탐색해가며 모든 영역을 반복하면 filter 차원과 동일한 이미지가 뽑히게 된다. 이는 원래 이미지를 압축시킨 결과로, convolution은 layer를 거칠수록 filter의 차원을 줄여가며 보다 더 추상적인(abstract) 정보를 뽑게 된다.
Weight sharing
convolution은 이미지의 각 영역에 동일한 filter(weight)를 곱하게 되는데, 이를 weight sharing이라 한다. 이는 추정해야할 파라미터 수를 줄일 수 있어 효율적인 학습이 가능하다.
2.2.2 Graph convolutional encoder
앞서 설명한 convolution의 2가지 특징은 gcn에도 그대로 적용된다. 이 특징들이 추천시스템에서 어떤 역할을 할지 고민해보았으면 한다.
아래 식은 gcn의 convolution이다. 여기서 $H$는 각 user, item에 대한 latent vector로 이뤄진 matrix이며, $W$는 weight로 추정해야할 파라미터다. 앞서 convolution은 원 데이터의 추상적인 정보를 뽑아내는 것이라 하였다. 여기서는 $W$가 filter같은 것으로 user, item에 대한 정보를 뽑는 역할을 한다.
\[\begin{align*} H=\psi(X,A) = \sigma(AXW) \end{align*}\]위 식은 graph convolution의 일반화 된 꼴이며 우리 논문에 따르면 이를 다음과 같이 표현한다. 여기서는 user $i$에 대한 latent vector $h_{i}$를 구하는 상황을 가정하며, layer의 개수는 $l$개로 한다. 무언가 복잡해 보이지만 결국 하는 일은 latent vector를 구하는 것임을 잊지말자.
\[\begin{align*} \\ h_{i(E_{1} \times 1)}^{(1)} & = \sigma \left[ \text{accum}(\sum_{j \in \mathcal{N}_{i,1}} \mu_{j \rightarrow i, 1}^{(0)} \ ,..., \sum_{j \in \mathcal{N}_{i,R}} \mu_{j \rightarrow i, R}^{(0)} ) \right], \ \ \mu_{j \rightarrow i, r}^{(0)} = W_{r}^{(0)}x_{j}^{T}, \ \ W_{r}^{(0)} \in R^{E_{1} \times D}, \ x_{j} \in R^{1 \times D} \\ h_{i(E_{2} \times 1)}^{(2)} & = \sigma \left[ \text{accum}(\sum_{j \in \mathcal{N}_{i,1}} \mu_{j \rightarrow i, 1}^{(1)} \ ,..., \sum_{j \in \mathcal{N}_{i,R}} \mu_{j \rightarrow i, R}^{(1)} ) \right] ,\ \ \mu_{j \rightarrow i, r}^{(1)} = W_{r}^{(1)}h_{i}^{(1)}, \ \ W_{r}^{(1)} \in R^{E_{2} \times E_{1}} \\ ... \\ h_{i(E_{l} \times 1)}^{(l)} & = \sigma \left[ \text{accum}(\sum_{j \in \mathcal{N}_{i,1}} \mu_{j \rightarrow i, 1}^{(l-1)} \ ,..., \sum_{j \in \mathcal{N}_{i,R}} \mu_{j \rightarrow i, R}^{(l-1)} ) \right] ,\ \ \mu_{j \rightarrow i, r}^{(l-1)} = W_{r}^{(l-1)}h_{i}^{(l-1)} , \ \ \ W_{r}^{(l-1)} \in R^{E_{l} \times E_{l-1}} \\ \\ \end{align*}\]우선 $\sigma, \text{accum}$ 등의 상세한 노테이션은 아래 예시에서 살펴보고, 여기서는 앞서 언급한 convolution의 2가지 특징을 중심으로 살펴보겠다. 또한 위 식에 $A$는 없는데 이것도 예시에서 함께 설명하겠다.
Weight sharing(message)
논문에서는 message란 개념을 도입한다. message는 edge를 통해 두 노드가 weight를 주고받는다는 측면에서 생겨난 개념이다. user $i$와 item $j$가 rating edge $r$로 연결될 때 message는 아래와 같이 정의된다.
\[\begin{align*} \mu_{j \rightarrow i, r} := W_{r}x_{j}^{T} \end{align*}\]결국 user $i$에 대한 latent vector는 인접 노드인 item $j$의 영향을 받으며, $W_{r}$( rating $r$에 대한 weight)공간에 item $j$를 표현(선형변환)하여 정의된다는 것이다. 두 노드는 서로 연결 되어있으니 반대도 다음과 같이 성립한다.
\[\begin{align*} \mu_{i \rightarrow j, r} := W_{r}x_{i}^{T} \end{align*}\]마찬가지로 item $j$의 latent vector는 인접 노드인 user $i$의 영향을 받으며, $W_{r}$공간에 user $i$를 표현하여 정의된다. 즉 식을 보면 알 수 있듯, 인접한 노드끼리는 같은 weight를 공유하고 있는 것이 핵심이다. 결국 학습을 거듭할수록 $W_{r} $공간은 rating $r$을 갖는 user, item의 정보들로 표현이 될 것이다. (필자는 graph를 도입한 이유가 여기있다고 보며 이 아이디어가 정말 경이롭다고 생각했다)
Abstract feature
앞서 cnn의 convolution은 layer를 거칠수록 filter차원을 줄여가며 추상적인(abstract) 정보를 뽑는다고 하였다. gcn도 마찬가지로 layer를 거칠수록 $W$의 차원을 줄여가며 더욱 추상적인 latent vector를 뽑을 수 있다. 예를 들어 첫 번째 layer에서 $E_{1}$차원의 $W_{r}^{(0)}$에 맵핑을 하고, 두 번째 layer에서는 $E_{2}(E_{2}<E_{1})$차원의 $W_{r}^{(1)}$에 맵핑하는 식이다. layer개수와 weight 차원은 학습시 선택하며, 논문에서는 multi layer가 큰 성과가 없어 1개만 사용했다고 한다.
Transformation
논문에서는 최종적으로 user $i$에 대한 latent vector $u_{i}$를 구하기 위해 다음과 같은 transformation을 거친다.
\[\begin{align*} u_{i(E_{1} \times 1)}^{(1)} &= \sigma(W^{(1)} h_{i}^{(1)}), \ \ W^{(1)} \in R^{E_{1} \times E_{1}} \\ u_{i(E_{2} \times 1)}^{(2)} &= \sigma(W^{(2)} h_{i}^{(2)}), \ \ W^{(2)} \in R^{E_{2} \times E_{2}} \\ ... \\ u_{i(E_{l} \times 1)}^{(l)} &= \sigma(W^{(l)} h_{i}^{(l)}), \ \ W^{(l)} \in R^{E_{l} \times E_{l}} \\ \end{align*}\]이 단계는 모든 $i$ 에 대해 동일한 weight $W$를 곱함으로써, 모든 user들을 같은 공간에 표현하는 것이다. 예를 들어 user1은 3점만 주는 사람이고, user2는 5점만 주는 사람이라면, 전자는 $W_{3}$공간에서만 학습이 됐을 것이고, 후자는 $W_{5}$공간에서만 학습이 됐을 것이다. 따라서 $u_{1}$과 $u_{2}$를 같은 공간인 $W$에 다시 표현함으로써 같은 결(?)로 학습될 수 있도록 하는 것이다. item도 user와 마찬가지로 $W$에 표현한다.
2.2.3 Graph convolutional encoder example
지금까지 개념적으로만 살펴봤다면 이제 구체적인 예를 들어보자. 해당 예시는 다음과 같이 user1이 item1과 item2에 각각 5점, 1점을 부여한 상황을 가정한다.

앞서 $h_{i }$는 다음과 같이 정의된다 하였다. 여기서 $\mathcal{N}_{i,r}$은 user $i$와 인접한 노드 중, rating $=r$을 만족하는 item 노드 집합을 나타낸다.
\[\begin{align*} h_{i(E \times 1)} & = \sigma \left[ \text{accum}(\sum_{j \in \mathcal{N}_{i,1}} \mu_{j \rightarrow i, 1} \ ,..., \sum_{j \in \mathcal{N}_{i,R}} \mu_{j \rightarrow i, R} ) \right] \end{align*}\]우리는 user1에 대해 보고있으니 $i = 1$이며, rating edge가 2개이므로 \(\mathcal{N}_{1,1}=\{ 2 \}, \ \mathcal{N}_{1,5}= \{ 1 \}\) 가 존재한다. 이를 바탕으로 할 때, \(h_{1}\) 은 다음과 같다.
\[\begin{align*} h_{1(E \times 1)} & = \sigma \left[ \text{accum}( \mu_{2 \rightarrow 1, 1} \ ,\ \mu_{1 \rightarrow 1, 5}) \right] \\ & = \sigma \left[ \text{accum}(W_{r=1}x_{j=2}^{T}, \ W_{r=5}x_{j=1}^{T}) \right] \end{align*}\]이어 message $\mu$가 다음과 같이 계산된다고 하자.
\[\begin{align*} \bullet \ \mu_{2 \rightarrow 1, 1} = W_{r=1}x_{j=2}^{T} & = \begin{bmatrix} W_{11}^{1} & W_{12}^{1} & ... & W_{1D}^{1} \\ W_{21}^{1} & W_{22}^{1} & ... & W_{2D}^{1} \\ ... & ... & ... & ... \\ W_{E1}^{1} & W_{E2}^{1} & ... & W_{ED}^{1} \\ \end{bmatrix} \begin{bmatrix} x_{21} \\ x_{22} \\ ... \\ x_{2D} \\ \end{bmatrix} = \begin{bmatrix} s_{21}^{1} \\ s_{22}^{1} \\ ... \\ s_{2E}^{1} \\ \end{bmatrix} \\ \\ \bullet \ \mu_{1 \rightarrow 1, 5} = W_{r=5}x_{j=1}^{T} & = \begin{bmatrix} W_{11}^{5} & W_{12}^{5} & ... & W_{1D}^{5} \\ W_{21}^{5} & W_{22}^{5} & ... & W_{2D}^{5} \\ ... & ... & ... & ... \\ W_{E1}^{5} & W_{E2}^{5} & ... & W_{ED}^{5} \\ \end{bmatrix} \begin{bmatrix} x_{11} \\ x_{12} \\ ... \\ x_{1D} \\ \end{bmatrix} = \begin{bmatrix} s_{11}^{5} \\ s_{12}^{5} \\ ... \\ s_{1E}^{5} \\ \end{bmatrix} \\ \end{align*}\]이때 $\text{accum}(.)=\text{sum}(.)$으로 가정하면 $h_{1}$은 다음과 같이 계산된다. 여기서 $\sigma(.)$는 activation function으로 논문에서는 relu를 사용했다.
\[\begin{align*} h_{1} = \begin{bmatrix} \sigma(s_{21}^{1} + s_{11}^{5}) \\ \sigma(s_{22}^{1} + s_{12}^{5}) \\ ... \\ \sigma(s_{2E}^{1} + s_{1E}^{5}) \\ \end{bmatrix} \end{align*}\]결국 user 1에 대한 latent vector $h_{1}$은 user1과 인접한 노드 item1, item2의 정보를 사용하여 계산된다는 것에 주목하자. 여기에 다른 item의 정보는 사용되지 않았다. 이는 cnn의 convolution이 영역을 한칸식 옮기며 주변 탐색해 가는 원리랑 비슷하다 .
또한 앞서 여기서는 adjacency matrix $A$를 사용하지 않는다고 했는데, 그 이유는 단순하다. $A$를 곱하는 이유는 (matrix 연산을 직접 해보면 알수 있듯) 인접 노드만 가져오기 위함인데, 여기서는 이미 인접 노드만 가져와서 계산을 하기때문에 굳이 고려할 필요가 없는 것이다.
2.3 Bilinear decoder
지금까지 encoder 모델을 살펴봤으니, 이제 decoder를 살펴볼 차례다.
\[\begin{align*} \hat{M}_{N_{u} \times N_{v}} =g(U,V) \end{align*}\]앞서 decoder는 encoder로부터 구한 user, item latent vector를 가지고 rating을 예측하는 것이라 하였다. 논문에서는 다음과 같이 계산한다.
\[\begin{align*} \hat{M_{ij}}= \sum_{r \in R} r \ p(\hat{M_{ij}} = r) , \ \ \text{where} \ \ p(\hat{M_{ij}} = r) = \frac{e^{u_{i}^{T}Q_{r}v_{j}}}{ \sum_{s \in R} e^{u_{i}^{T}Q_{s}v_{j}} } \end{align*}\]즉 item $j$에 대한 user $i$의 rating은 rating을 가중평균해서 예측하며, 이때 가중치로 \(p(\hat{M_{ij}} = r)\)를 사용한다. 여기서 $Q_{r}$은 encoder모델의 $W_{r}$과 같은 parameter matrix다.
2.4 Model training
이제 encoder, decoder를 각각 살펴봤으니 여기서는 모델이 어떻게 학습되는지 살펴보자. 여기서는 loss function의 정의만 보고 넘어가겠다.
\[\begin{align*} \mathcal{L} = -\sum_{i,j ;\ \Omega_{i,j}=1} \sum_{r=1}^{R} I[r=M_{ij}] \log p(\hat{M_{ij}}=r) , \ \ \Omega \in \{ 0,1 \}^{N_{u} \times N_{v}} \end{align*}\]여기서 $\Omega$는 rating matrix $M$의 observed 원소에 대해서는 1, unobserved 원소에 대해서는 0으로 채운 mask matrix다. 이를 고려한 이유는 observed 데이터만 학습하기 위해서다.
위 식은 자세히 보면 베르누이 분포의 likelihood와 형태가 동일하다. 따라서 결과적으로 negative likelihood를 $\mathcal{L}$ 을 최소화 하는 parameter \(\Theta= \{ W, W_{r}, Q_{r} \}\) 를 찾는 것이 목표가 되겠다.
2.5 Input feature representation and side information
앞서 graph구조는 side information을 표현하기 용이하다고 했다. 논문에서는 다음과 같은 방식으로 side information을 허용한다. 즉 적절한 정보 $f_{i}$를 정의한 다음 transformation 단계에 더해주는 식이다.
\[\begin{align*} u_{i} = \sigma(Wh_{i} + W_{2}^{f}f_{i}) \ \ \text{with} \ \ f_{i}= \sigma(W_{1}^{f}x_{i}^{f} + b) \end{align*}\]이때 $W_{1}^{f}, W_{2}^{f}$역시 추정해야할 파라미터가 된다.
3. Conclusion
지금까지 graph based recommendation system을 살펴봤다. 그중 논문이 제시한 아이디어는 graph구조를 사용해서 rating matirx를 예측하는 시스템으로, 크게 encoder와 decoder로 이뤄져 있음을 확인했다. 정리하자면 encoder를 통해 user, item에 대한 latent vector를 구하고, decoder를 통해 rating을 예측하는 시스템이 되겠다. 대체적으로 matrix factorization 기반 추천 알고리즘들은 matrix completion이라는 문제를 풀게 되는데, 이 논문은 그 방법이 graph일 뿐임을 잊지말자.
Leave a comment